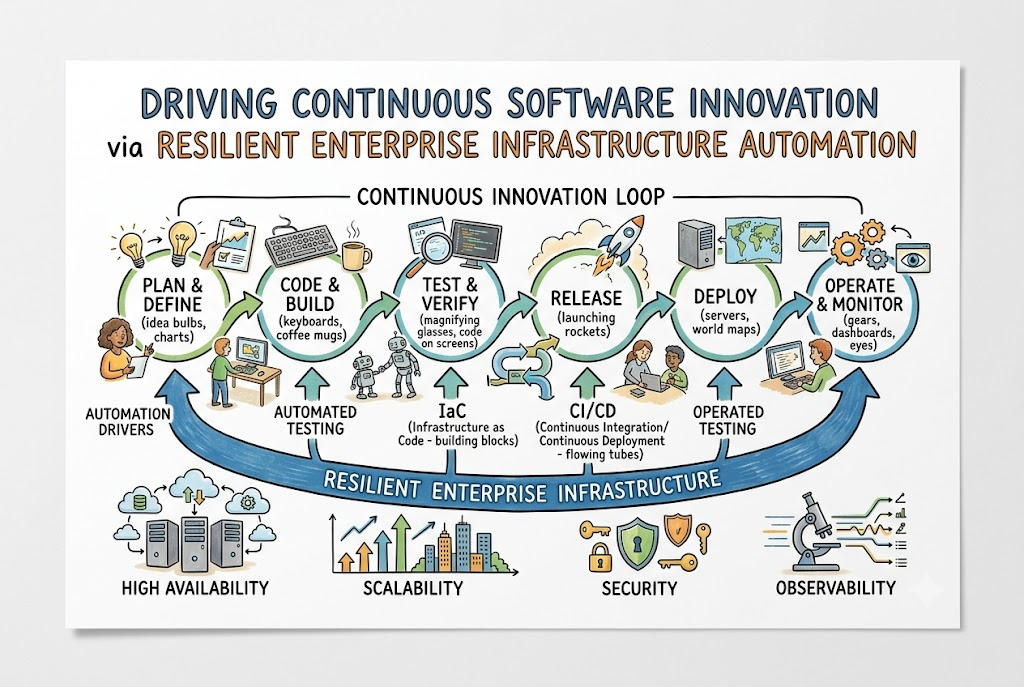
Organizations frequently stumble when trying to release software updates quickly while ensuring application uptime. This friction usually stems from deep-rooted process gaps between development teams and operations engineers, which delays features and hurts customer satisfaction. To fix these core structural inefficiencies, progressive technology leaders join forces with Cotocus, an elite DevOps Consulting Company that builds highly agile, completely automated delivery ecosystems.
Transforming Code Delivery with Automated Deployment Rails
Manual software compilation and testing introduce human errors and slow down critical product launches. Because of these challenges, corporate engineering teams integrate professional DevOps Consulting Services to build high-velocity release pathways. Forward-thinking software teams establish specialized CI/CD Pipeline Consulting frameworks that move code contributions instantly from developer machines to cloud clusters. Furthermore, engineering leaders deploy structured Infrastructure Automation Consulting to define complex server environments entirely through code templates, which guarantees perfect environments across all staging tiers.
A reliable, modern automated environment relies on three specific operational foundations:
- Declarative server blueprints that permanently stop environment configuration drift.
- Programmatic inspection checks that validate code safety during every build step.
- Instantaneous deployment rollback switches that shield users from system glitches.
Overcoming Cloud Multi-Tenancy and Developer Friction
Running microservice architectures across public cloud environments creates significant network and scaling complexities. As a result, businesses look to comprehensive Cloud Consulting Services to design secure, isolated, multi-tenant cluster layouts. When moving away from restrictive on-premise systems, enterprise leaders execute highly targeted Cloud Migration Services to securely shift database backends without disrupting current consumer applications.
| Infrastructure Strategy | Legacy VM Management | Self-Service Internal Platforms |
| Provisioning Model | Manual operations tickets filled out by engineers. | API-driven portals managed via automated scripts. |
| Resource Tuning | Static allocations that cause wasted cloud spend. | Dynamic scaling that shifts based on real-time traffic. |
To maximize daily engineering output, tech organizations invest in Platform Engineering Consulting to build streamlined internal developer portals. This software configuration approach allows engineers to self-provision required testing environments on demand without waiting for sysadmin approvals. Consequently, development teams dedicate their valuable hours to shipping product features rather than fixing cloud environment errors.
Orchestrating Live Clusters with Immutable Declarative Workflows
Managing complex application packages across large server farms introduces major load distribution and scheduling difficulties. To resolve this, enterprise teams leverage professional Kubernetes Consulting Services to automate container scheduling, manage network loads, and self-heal damaged application instances. Even so, configuring container setups by hand often introduces configuration errors and creates inconsistencies across cluster nodes.
[Developer Code Push] ──> [Git Pull Request Approved] ──> [Automated GitOps Sync] ──> [Live Kubernetes Update]
Code language: CSS (css)To preserve absolute synchronization between your configuration plans and live clusters, engineering groups adopt GitOps Consulting Services to govern system states. This operational pattern establishes your git repository as the absolute source of truth for your entire server footprint. Approved pull requests trigger instant, automated synchronizations across your production clusters, providing a perfectly transparent and easily auditable history of all environment updates.
Boosting Platform Resilience with Proactive Systems Monitoring
Unexpected software outages directly reduce corporate profits and weaken consumer trust. Because of this major risk, corporate technology groups deploy SRE Consulting Services to apply rigorous computer science principles directly to infrastructure environments. System engineers establish explicit service level objectives to balance software launch speed with high cluster availability. By adopting proactive Site Reliability Engineering Consulting practices, software teams switch their everyday focus from reactive firefighting to continuous platform hardening.
| Metric | DevOps Perspective | SRE Execution |
| Primary Metric | Maximize continuous integration and shipping speeds. | Secure high platform uptime and system performance. |
| Key Indicator | Code deployment frequency and build speed. | Error budget metrics and mean time to repair. |
This reliable production environment helps software teams insert automated security checkposts directly into their delivery pipelines. Instead of conducting slow compliance checks right before a public software release, organizations rely on DevSecOps Consulting Services to scan application code continuously. Automated compliance tools flag vulnerabilities during early software compilation runs, which allows developers to fix security issues long before code arrives in a live production environment.
Unleashing Data Optimization through Intelligent Automation Platforms
Modern enterprise platforms produce massive quantities of log data that easily overwhelm traditional monitoring tools. To solve this problem, forward-thinking tech departments utilize AIOps Consulting Services to analyze live data telemetry and pinpoint system anomalies using machine learning engines. This artificial intelligence overlay significantly shortens the time required to diagnose and fix deep production software bugs.
Simultaneously, managing advanced machine learning models demands unique deployment methods. For this reason, business leaders implement MLOps Consulting Services to systematically manage the entire model lifecycle from early validation to production inference. In parallel, teams implement DataOps Consulting Services to automate data quality checks, structural transformations, and pipeline mechanics, which ensures data analysis teams always utilize highly reliable data assets.
Upgrading Internal Engineering Skills with Corporate Learning
Infrastructure modernizations inevitably fail if internal development squads lack the skills to operate the new software stack. To establish deep internal capabilities, corporate leaders schedule customized DevOps Corporate Training programs that align technical teams with modern automation tools. Providing structured technical courses prevents tool abandonment and ensures long-term operational consistency.
Stage 1: Core CI/CD Flows ──> Stage 2: Cloud Architectures ──> Stage 3: Container Management ──> Stage 4: DevSecOps Governance
Targeted upskilling programs address specific knowledge gaps across different engineering branches. Enterprises organize customized DevOps Training for Companies to unite developers and systems engineers under shared automation goals. Furthermore, technical departments deploy focused Kubernetes Corporate Training sessions to help their developers master complex container management workflows. Finally, companies leverage specialized DevSecOps Corporate Training courses to build a security-first culture deep within daily programming routines.
Essential Engineering Concepts
- Continuous Integration — Merging code updates into a shared repository multiple times per day to trigger automated verification scripts.
- Infrastructure as Code — Defining, provisioning, and managing cloud environments through machine-readable configuration profiles instead of manual browser tweaks.
- Container Orchestration — Automating the deployment, scaling, management, and networking of containerized software packages across server clusters.
- GitOps — Operating infrastructure networks by utilizing Git pull requests to control live cluster state configurations and automated deployments.
- Service Level Objectives — Quantifiable performance targets that specify the required uptime and response speed of a running software system.
- Chaos Engineering — Introducing intentional component failures into a production environment to verify and improve systemic platform resilience.
- Observability — Assessing the internal health of a complex environment by analyzing its external logs, metrics, and traces.
These engineering concepts connect directly because programmable cloud environments provide the rich telemetry and automation hooks needed to run smart observability engines and continuous security scanners.
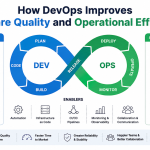
SRE vs. DevOps — Navigating the Operational Boundaries
Companies frequently blur the lines between delivery optimization and platform reliability, creating confusion over who owns production health. The table below outlines the structural differences between these two methodologies.
| Operational Dimension | DevOps Philosophy | Site Reliability Engineering (SRE) |
| Core Idea | Cultural shift designed to break down developer and operations siloes. | Engineering discipline focused on cluster health and system scalability. |
| Operational Focus | Emphasizes the pre-deployment software development cycle. | Emphasizes the post-deployment system execution timeframe. |
| Workflow Ownership | Owns the automated compilation and software delivery loop. | Owns system availability, application latency, and server utilization. |
| Common Blunder | Expecting automated software tools to resolve deep cultural divisions. | Enforcing absolute platform uptime at the expense of product updates. |
| Everyday Task | Configuring a GitLab runner to assemble code containers. | Writing automated auto-scaling scripts for cloud compute networks. |
Confusing these two operational strategies damages your release pipeline and creates accountability gaps. Consequently, feature delivery drops because neither team clearly owns the boundary where automation code interacts with active system environments.
Real-World Field Implementations
The list below outlines how diverse corporations utilize tailored platform consulting to fix critical infrastructure challenges.
- Digital Banking Institution — Manual compliance reviews delayed code deployments by several weeks -> Incorporated automated DevSecOps validation scanners into the build loop -> Reduced regulatory compliance check times by eighty percent.
- Online Retail Giant — Massive user traffic surges routinely crashed database clusters during seasonal holiday sales -> Shifted monolithic codebases to auto-scaling Kubernetes nodes -> Eliminated checkout page downtime during peak traffic events.
- Healthcare Provider Network — Fragmented data storage formats caused frequent sync errors across patient databases -> Engineered a unified, automated DataOps orchestration track -> Attained real-time data consistency across all healthcare facilities.
- Supply Chain SaaS Company — Hidden memory leaks caused unexpected application outages during overnight shifts -> Deployed proactive AIOps anomaly monitoring tools -> Reduced critical infrastructure alerts by sixty percent.
Common Strategic Failure Patterns
- Treating automation as a pure tooling shift — Leaders purchase expensive software licenses without updating team workflows, which merely automates existing bad habits.
- Postponing security checks until final production delivery — Engineering groups focus solely on deployment speed, which ultimately exposes live clusters to unverified code vulnerabilities.
- Building over-engineered, bespoke internal platforms — Systems engineers write fragile, custom automation scripts instead of choosing open industry standards, accumulating massive technical debt.
- Neglecting team education during major cloud adoptions — Management implements complex cloud networks without upskilling internal teams, causing developer frustration and low tool adoption.
- Setting up overly sensitive monitoring alert triggers — Operations teams activate notifications for minor system metrics, creating alert fatigue that causes engineers to miss critical production warnings.
- Choosing flawed cloud migration techniques — Moving legacy monoliths directly to cloud servers without containerizing them increases operational costs without delivering any performance boosts.
Modern Transformation Blueprint
- Pipeline Standardization — Centralize all source code under a unified platform and add automated testing scripts to check every single developer update immediately.
- Infrastructure Programmability — Migrate local computing workloads to high-availability cloud platforms and define all infrastructure through declarative templates.
- Orchestrated Containerization — Convert monolithic software into small, modular microservices managed by Kubernetes to achieve effortless scaling and fault isolation.
- Reliability and Ongoing Upskilling — Apply strict site reliability engineering rules, deploy automated security checkposts, and launch corporate upskilling programs to secure long-term platform health.
Why Cotocus
Partnering with an experienced Digital Transformation Consulting Company like Cotocus empowers you to align your software delivery outputs with overarching business growth goals. The agency clears away technical debt by constructing custom cloud frameworks, deploying intelligent systems monitoring tools, and running targeted upskilling camps for internal engineering teams. Their cross-functional consulting squads ensure that your business receives both advanced computing environments and the deep process knowledge required to maintain a secure, highly efficient software release lifecycle.
FAQ Section
- How do DevOps consulting services accelerate software delivery speeds?These consulting offerings replace manual configuration steps with automated validation and shipping pipelines. This workflow update allows developers to safely push new feature changes to live servers within minutes instead of waiting weeks.
- What specific business advantages does platform engineering provide to development teams?Platform engineering sets up unified internal developer portals that allow engineers to provision required compute resources instantly. This modern setup removes IT helpdesk ticket queues and permits developers to focus entirely on writing application code.
- Why should an enterprise select GitOps workflows over traditional deployment methodologies?GitOps workflows treat git repositories as the definitive source of truth for all operational environment layouts. This practice provides a clear, unalterable deployment history and allows for fast disaster recovery by automatically syncing cluster states.
- How do site reliability engineering metrics balance development velocity with system stability?SRE practices utilize mathematical error budgets to calculate the maximum allowable amount of application downtime. This tool allows teams to deploy new features quickly until the budget empties, which instantly switches team focus back to system stabilization.
- What makes automated security integration preferable to traditional security compliance reviews?Automated security tools parse application source code for flaws during early compilation routines. This approach surfaces structural risks immediately, preventing costly deployment bottlenecks before a public launch.
- When should an organization invest in specialized data engineering pipeline automation?Enterprises require automated data paths when manual file processing triggers data corruption or delays business intelligence reporting. Automated data paths ensure data teams consistently view clean, validated information for real-time analysis.
Operational Summary
Maintaining a competitive software advantage requires an integrated blend of automated pipelines, continuous security guardrails, and deep internal technical literacy. Modern companies must continuously upgrade their infrastructure deployment patterns to defend their market position. To turn your legacy deployment setups into high-velocity engines, visit Cotocus and book an initial operational capability review.




Leave a Reply
You must be logged in to post a comment.