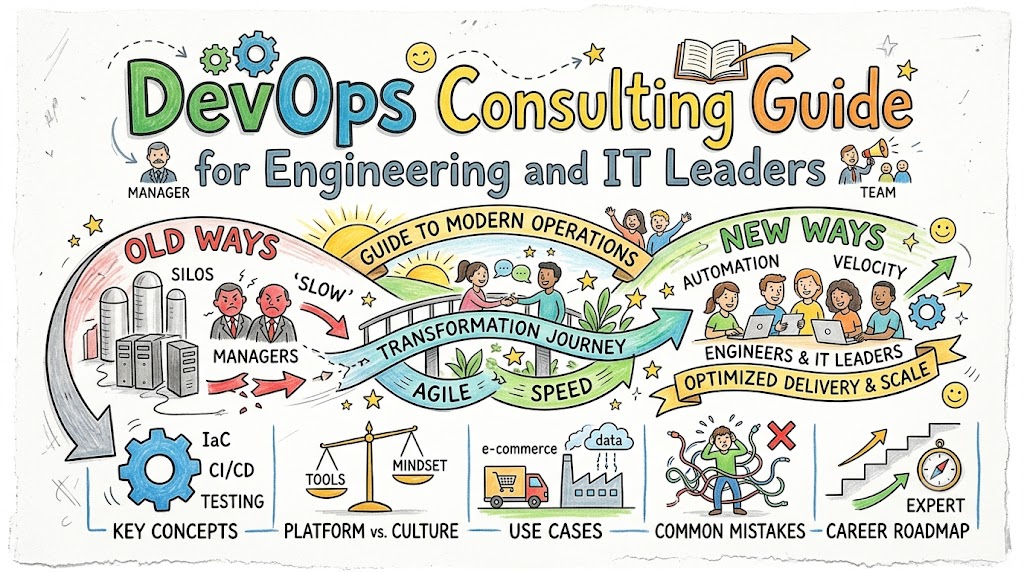
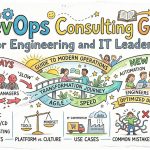
Modern software delivery demands velocity, reliability, and scale, yet bridging the gap between raw infrastructure and rapid deployment remains a significant hurdle. Consequently, engineering and IT leaders often find themselves navigating complex technical ecosystems while attempting to maintain high organizational efficiency. This comprehensive DevOps Consulting Guide for Engineering and IT Leaders breaks down the core pillars of operations engineering, clarifying how structured strategic alignment transforms standard development practices into a scalable, high-performing pipeline. By analyzing infrastructure management, cultural patterns, and deployment architectures, this guide serves as an essential framework for executives driving digital transformation.
To successfully execute these advanced strategies, many organizations collaborate with experienced industry specialists who understand the intricate balance of automation and architecture. For instance, working with an expert like Rajeshkumar provides teams with the precise architectural foresight needed to eliminate delivery bottlenecks and optimize cloud expenditures. Ultimately, establishing a robust operational model requires a clear understanding of modern automated workflows, cultural transformation, and common deployment pitfalls, all of which we explore in depth below.
Key Operational Concepts You Must Know
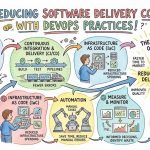
Infrastructure as Code (IaC)
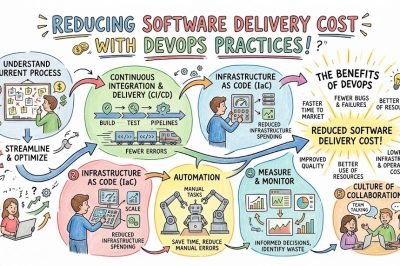
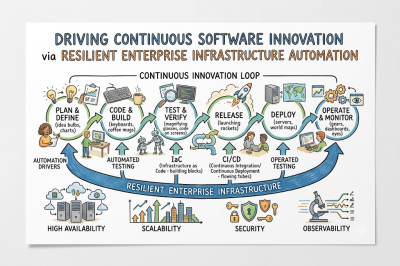
Managing cloud environments manually through interactive dashboards creates immense inconsistency, configuration drift, and unrepeatable environments across engineering teams. Therefore, modern operations engineering relies heavily on treating infrastructure exactly like software application code, utilizing declarative files to define resources. By writing down infrastructure definitions, teams can version-control their networks, servers, and storage databases using Git repositories, ensuring absolute predictability.
Furthermore, this systematic approach allows engineering teams to provision identical staging, testing, and production environments with complete automation and minimal human intervention. As a result, code-driven infrastructure mitigates the risks of manual misconfiguration while accelerating disaster recovery timelines through rapid, automated resource deployment.
Continuous Integration and Continuous Deployment (CI/CD)
Siloed development cycles often lead to massive, high-risk code integrations that break existing production environments and disrupt active user sessions. To solve this critical bottleneck, continuous integration ensures that developers frequently merge their code changes into a centralized main repository branch. Each code commit triggers an automated pipeline that compiles the application, runs automated test suites, and flags syntax errors immediately.
Subsequently, continuous deployment takes those validated builds and automatically pushes them directly into the production environment without manual delays. Consequently, this seamless automated pipeline drastically reduces the time-to-market for new features while maintaining strict software quality and operational stability.
Observability and Telemetry
Traditional system monitoring simply alerts operations teams when a server crashes, but it completely fails to explain why the system degraded. On the other hand, comprehensive observability provides deep, real-time insights into internal system states by analyzing metrics, logs, and distributed traces. Metrics track resource usage trends, logs provide detailed historical context, and distributed traces follow individual user requests across complex microservices.
Therefore, implementing robust telemetry systems allows engineering leaders to proactively identify hidden performance bottlenecks before they impact end-users. Ultimately, a well-engineered observability framework transforms reactive troubleshooting into a proactive, data-driven optimization process that guarantees high system availability.
Platform Implementation vs. Culture — What’s the Real Difference?
| Operational Aspect | Platform Implementation | Cultural Transformation |
|---|---|---|
| Primary Focus | Deploying software automation tools, cloud systems, and automated CI/CD frameworks. | Shifting team mindsets, breaking communication silos, and shared accountability. |
| Core Components | Kubernetes clusters, Git repositories, monitoring tools, and IaC scripts. | Blameless post-mortems, continuous learning, and cross-functional feedback loops. |
| Measurement Metrics | Deployment frequency, pipeline execution speed, and infrastructure uptime percentages. | Team collaboration levels, psychological safety, and rapid problem ownership. |
| Implementation Risk | Tool sprawl, high licensing costs, and overly complex technical configurations. | Employee resistance to change, cultural inertia, and leadership misalignment. |
The Tooling Trap
Many engineering organizations mistakenly assume that purchasing expensive software tools will instantly solve their deep-rooted operational inefficiencies. However, deploying a complex platform without changing how teams interact merely automates existing bad habits and increases technical debt. Tools are simply accelerators, meaning that if your underlying delivery processes are fundamentally broken, automation will only accelerate failures.
Therefore, leaders must understand that technology alone cannot fix communication gaps or poor architectural planning within an enterprise. Instead of chasing shiny software platforms, organizations should focus on optimizing their workflows before applying automated engineering solutions.
Cultivating Shared Responsibility
True operational excellence requires a profound shift in organizational culture, moving away from traditional siloed development and operations teams. In the past, developers built software features and blindly threw them over the wall to operations teams for deployment. In contrast, a mature operational culture fosters shared ownership, where developers care about stability and operations teams understand feature velocity.
Consequently, this collaborative mindset reduces finger-pointing during production outages and encourages teams to solve system bugs together. By institutionalizing blameless post-mortems, companies transform system failures into valuable learning opportunities that strengthen overall infrastructure resilience.
Real-World Use Cases of Modern Operations
High-Velocity E-Commerce Scaling
During flash sales or major holiday shopping events, e-commerce platforms experience sudden, massive spikes in concurrent user traffic. Standard static infrastructure quickly buckles under this intense load, resulting in dropped checkout transactions and severe revenue losses. By leveraging automated scaling architectures, modern online retailers can dynamically expand their compute capacity in response to real-time traffic metrics.
Simultaneously, containerized microservices allow developers to deploy critical hotfixes to the checkout system without taking down the entire website. Thus, operations engineering ensures uninterrupted user experiences, preserving brand reputation and maximizing transaction volumes during peak demand windows.
Financial Technology Compliance and Security
Financial institutions handle highly sensitive customer data and must adhere to strict regulatory compliance frameworks while maintaining rapid delivery cycles. To balance these competing priorities, engineering teams integrate automated security scanning directly into their active deployment pipelines. This strategy, frequently called DevSecOps, scans application dependencies for known vulnerabilities and inspects infrastructure configurations before code ever reaches production.
As a result, compliance audits become continuous and fully automated, replacing stressful, manual end-of-month verification procedures. Therefore, fintech organizations can confidently innovate at high speeds while ensuring that security protocols remain uncompromised and fully auditable.
Healthcare System Reliability
In the healthcare sector, application downtime can directly disrupt patient care access, making system reliability a literal matter of life and death. Consequently, healthcare IT leaders deploy multi-region, highly available cloud architectures with automated failover mechanisms to guarantee constant application uptime. If a primary cloud data center experiences a physical hardware outage, traffic is instantly rerouted to a synchronized backup region.
Additionally, isolated database architectures ensure that patient health records remain securely encrypted both during transit and while resting in cloud storage. Through these robust operational guardrails, healthcare platforms maintain strict data integrity and continuous availability for medical professionals worldwide.
Common Mistakes in Operations Engineering
Over-Engineering the Architecture
Engineers often fall into the trap of designing hyper-complex systems that far exceed the actual business requirements of the organization. For example, deploying a massive, multi-cluster Kubernetes framework for a simple, low-traffic internal business application introduces massive operational overhead. This unnecessary complexity makes troubleshooting incredibly difficult, extends onboarding timelines for new developers, and inflates monthly cloud computing bills.
Therefore, consulting leaders must constantly advocate for architectural simplicity, ensuring that infrastructure designs directly align with current business goals. Building for hypothetical scale that your application does not yet require creates fragile, unmanageable systems that drain engineering resources.
Ignoring Technical Debt
In the rush to deliver new software features to the market, teams frequently take shortsighted shortcuts with their infrastructure configurations. They might write messy, hardcoded configuration files or delay critical security patches on underlying operating systems to save deployment time. Over time, these unaddressed shortcuts accumulate as massive technical debt, leaving environments unstable, insecure, and highly unpredictable.
Eventually, the engineering team spends more time fixing broken infrastructure than developing revenue-generating software features for the business. To prevent this operational stagnation, leadership must dedicate consistent sprint cycles to refactoring infrastructure code and updating system dependencies.
Inadequate Security Integration
Treating security as an afterthought that occurs right before a major software release is an incredibly dangerous operational practice. When security audits happen at the absolute end of the delivery cycle, discovering a critical flaw forces costly project delays. Furthermore, developers are forced to completely re-architect large portions of code, destroying team morale and missing market windows.
Instead, operations engineering must bake security protocols directly into the earliest phases of the automated software development lifecycle. By shifting security left, potential vulnerabilities are caught and remediated in real time, drastically reducing enterprise risk profiles.
How to Become an Operations Expert — Career Roadmap
Foundational Knowledge
- Master Linux Systems: Learn core operating system concepts, file systems, process management, and deep network configuration patterns.
- Understand Networking: Grasp the fundamentals of TCP/IP, DNS routing, load balancing configurations, and modern HTTP protocol behaviors.
- Learn a Scripting Language: Develop strong proficiency in Python or Bash to effectively automate repetitive, manual administrative tasks.
Advanced Engineering Skills
- Adopt Cloud Platforms: Gain deep expertise in managing major cloud environments like AWS, Azure, or Google Cloud Platform.
- Implement Containerization: Master Docker container creation and learn to orchestrate large-scale, production-grade workloads utilizing Kubernetes clusters.
- Build Automated Pipelines: Design, secure, and maintain complex CI/CD workflows using industry-standard platforms like GitLab or Jenkins.
Strategic Leadership Mastery
- Align Infrastructure with Business: Learn to translate technical metrics like deployment frequency into clear, high-level business value.
- Optimize Cloud Costs: Master financial operations strategies to eliminate wasted cloud resources and maximize corporate infrastructure budgets.
- Foster Collaborative Engineering Cultures: Develop the soft skills necessary to break down organizational silos and lead cross-functional teams.
FAQ Section
- What is the primary objective of a DevOps consulting engagement?
The primary objective centers on aligning an organization’s software development workflows with its active IT infrastructure operations. By identifying architectural bottlenecks and cultural silos, a consulting expert helps enterprises accelerate software release cycles while increasing system reliability. Ultimately, this strategic partnership transforms chaotic, manual deployment practices into structured, automated, and highly predictable delivery pipelines.
- How does Infrastructure as Code prevent configuration drift across environments?
Infrastructure as Code prevents drift by serving as the absolute single source of truth for all environment setups. Because all servers, networks, and databases are explicitly defined in version-controlled text files, manual modifications are completely blocked. Any changes to the environment must go through the code review process, ensuring that staging and production remain identical.
- Why is cultural transformation considered harder than tool implementation?
Altering human behavior, ingrained team habits, and legacy organizational structures requires sustained leadership commitment and psychological safety. While installing a new software tool can happen in a few hours, changing how people communicate takes months. Resistance to change, fear of failure, and traditional siloed mindsets require careful mentorship, empathy, and consistent cultural reinforcement.
- What metrics should engineering leaders track to measure operational success?
Leaders should focus on the four core DORA metrics: deployment frequency, lead time for changes, mean time to recover, and change failure rate. Tracking these specific data points provides a clear, objective view of both delivery velocity and overall system stability. Over time, optimizing these metrics ensures that the engineering organization balances high speed with exceptional software quality.
- When should a growing startup consider migrating to a microservices architecture?
A startup should migrate only when a monolithic application creates clear organizational bottlenecks or severe technical scaling limitations. If multiple engineering teams are constantly stepping on each other’s toes during deployments, breaking up the codebase makes sense. However, moving to microservices prematurely introduces massive operational complexity that can easily overwhelm a small, resource-constrained team.
Final Summary
Successfully navigating the modern operational landscape requires a balanced fusion of robust platform automation and a healthy engineering culture. As outlined in this guide, mastering key concepts like Infrastructure as Code, CI/CD, and deep observability forms the foundation of enterprise velocity. However, technical tools alone cannot solve systemic inefficiencies without a parallel commitment to shared responsibility and cross-functional alignment. By avoiding common pitfalls like over-engineering and unmanaged technical debt, IT leaders can build resilient, highly scalable architectures. Ultimately, investing in strategic operational engineering drives sustainable business growth, turning infrastructure from a cost center into a competitive advantage.


Leave a Reply
You must be logged in to post a comment.