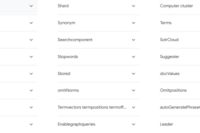
Here’s a table summarizing some common Solr command-line options along with their descriptions:
| Command | Description |
|---|---|
start | Starts Solr. Can include options for port, memory, etc. |
stop | Stops a running Solr server. |
restart | Restarts Solr. Useful for applying new configurations. |
status | Checks the current status of Solr instances. |
create | Creates a new Solr core or collection. |
delete | Deletes an existing Solr core or collection. |
version | Displays the current version of Solr. |
-f | Runs Solr in the foreground, useful for monitoring logs directly. |
These commands are typically executed from within the bin directory of your Solr installation. Each command might have additional options and flags to control its behavior more precisely.
./solr -h
Usage: solr COMMAND OPTIONS
where COMMAND is one of: start, stop, restart, status, healthcheck, create, create_core, create_collection, delete, version, zk, auth, assert, config, export, api, package, post, postlogs
Standalone server example (start Solr running in the background on port 8984):
./solr start -p 8984
SolrCloud example (start Solr running in SolrCloud mode using localhost:2181 to connect to Zookeeper, with 1g max heap size and remote Java debug options enabled):
./solr start -c -m 1g -z localhost:2181 -a "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=1044"
Omit '-z localhost:2181' from the above command if you have defined ZK_HOST in solr.in.sh.
Pass -help or -h after any COMMAND to see command-specific usage information,
such as: ./solr start -help or ./solr stop -h
Code language: JavaScript (javascript)Apache Solr can be started with several different commands and options
# Basic Start
# This command starts Solr on the default port 8983 with the default settings.
solr start
# Specifying the Port
# This command starts Solr on a specified port, in this case, 8984.
solr start -p 8984
# Running Solr in Cloud Mode
# This starts Solr in cloud mode, which enables running Solr with distributed clustering using
solr start -c
# Specifying ZooKeeper Connection for Cloud Mode
# This starts Solr in cloud mode and specifies the ZooKeeper connection string (here, ZooKeeper running on localhost at port 2181).
solr start -c -z localhost:2181
# Using a Specific Solr Home Directory
# This command starts Solr with a specified SOLR_HOME directory.
solr start -s /path/to/solr/home
# Running Solr on a Specific Java Virtual Machine
# This sets the Java home before starting Solr, useful if you have multiple Java installations.
SOLR_JAVA_HOME=/path/to/java/home solr start
# Increasing Java Memory
# This starts Solr with increased Java heap space, here setting the heap size to 4 gigabytes.
solr start -m 4g
# Starting with Custom Solr Configuration
# This allows you to pass custom Java system properties to Solr at startup.
solr start -a "-Dsolr.someConfig=someValue"
# Starting Solr with Debugging Options
# This command starts Solr with Java debugging enabled, allowing a debugger to attach on port 1044.
solr start -a "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=1044"
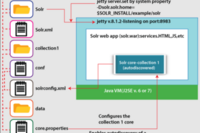
Code language: PHP (php)What is Running Solr in Cloud Mode?
Running Apache Solr in Cloud Mode refers to operating Solr in a distributed, scalable, and fault-tolerant configuration using SolrCloud. This mode is designed to provide enhanced capabilities that are crucial for managing large datasets across multiple servers, ensuring high availability and resilience in production environments. Here are some key aspects of running Solr in Cloud Mode:
- Distributed Indexing and Search: SolrCloud allows data to be indexed and searched across multiple Solr instances (nodes). This distribution helps in handling large volumes of data more efficiently than a single instance could manage.
- Automatic Load Balancing and Failover: SolrCloud automatically balances query load across different nodes and can reroute traffic in the event of node failure, improving both performance and reliability.
- Central Configuration Management: SolrCloud uses Apache ZooKeeper, a centralized service for maintaining configuration information and providing distributed synchronization. ZooKeeper keeps track of the status of the Solr cluster nodes and their configurations, making it easier to manage cluster-wide settings and consistently apply changes.
- Scalability: You can add or remove nodes from the SolrCloud cluster as needed. ZooKeeper updates its records accordingly, and Solr ensures that the data is rebalanced across the available nodes. This makes scaling up to handle more data or scaling down to conserve resources relatively straightforward.
- Real-time Replication: Data added to one node can be automatically replicated to other nodes, ensuring that copies of the data are available for redundancy and that the load is distributed for faster search performance.
- Sharding Support: SolrCloud supports sharding, which divides the data into subsets (shards) that can be hosted on different nodes. This is useful for managing very large datasets by distributing the data across the cluster.
- High Availability: The combination of automatic failover and data replication helps ensure that the Solr service remains available even if some of the nodes fail.




Leave a Reply
You must be logged in to post a comment.