How Apache Solr works?
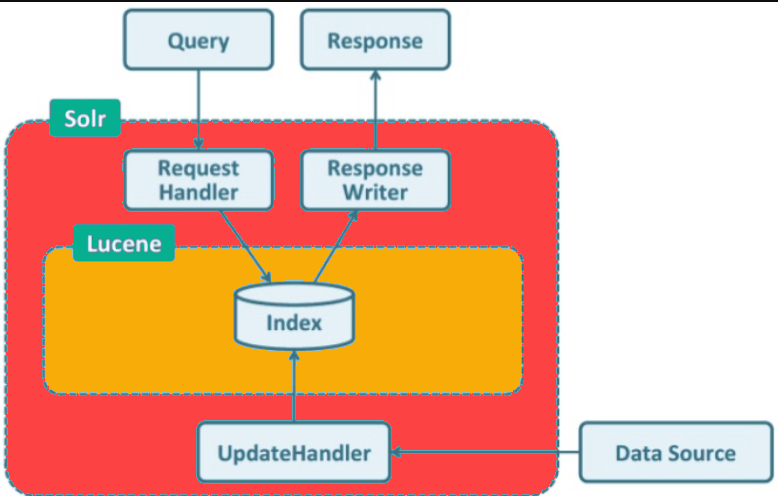
Apache Solr is a powerful, scalable open-source search platform built on Apache Lucene, which is a high-performance, full-featured text search engine library. Solr is widely used for enterprise search and analytics use cases because it can handle large volumes of data and offers features such as full-text search, faceted search, real-time indexing, and rich document handling. Here’s a basic overview of how Solr works:
1. Indexing
- Data Ingestion: Solr can ingest data from various sources such as databases, files, and websites. This data can be in various formats, including XML, JSON, CSV, and more.
- Document Addition: During the indexing process, the data is converted into documents. Each document is composed of fields, which Solr stores and indexes according to configurations specified in the
schema.xmlfile. This schema defines the field types, characteristics (such as tokenized, stored, indexed), and other attributes. - Tokenization and Analysis: Text fields are processed through analyzers which tokenize the text (breaking text into pieces, typically words) and may apply transformations like converting to lowercase, removing stop words, or applying synonyms. This process is critical for supporting effective and efficient search.
2. Searching
- Query Processing: When a search query is received, Solr parses and interprets the query based on the defined query syntax. The user can perform complex searches using various features such as boolean operators, wildcard characters, phrase queries, and more.
- Query Execution: Solr searches the indexed data for matches to the query. This can involve scanning indexes, ranking results based on relevance (using Lucene’s scoring algorithm), and applying any query-time boosts or functions.
- Faceting and Aggregations: Solr supports faceted search, which allows users to explore search results by categorizing them into “facets” based on the indexed fields. Additionally, Solr can perform various statistical calculations or aggregations on the dataset.
3. Results Handling
- Returning Results: Solr formats the query results and returns them to the user. This can include not just the matching documents, but also metadata such as the total number of matches, faceted counts, highlight snippets, and other analytics.
- Customizations and Extensions: Users can customize the output format (e.g., XML, JSON), modify query responses (e.g., using XSLT), and extend Solr’s capabilities through plugins.
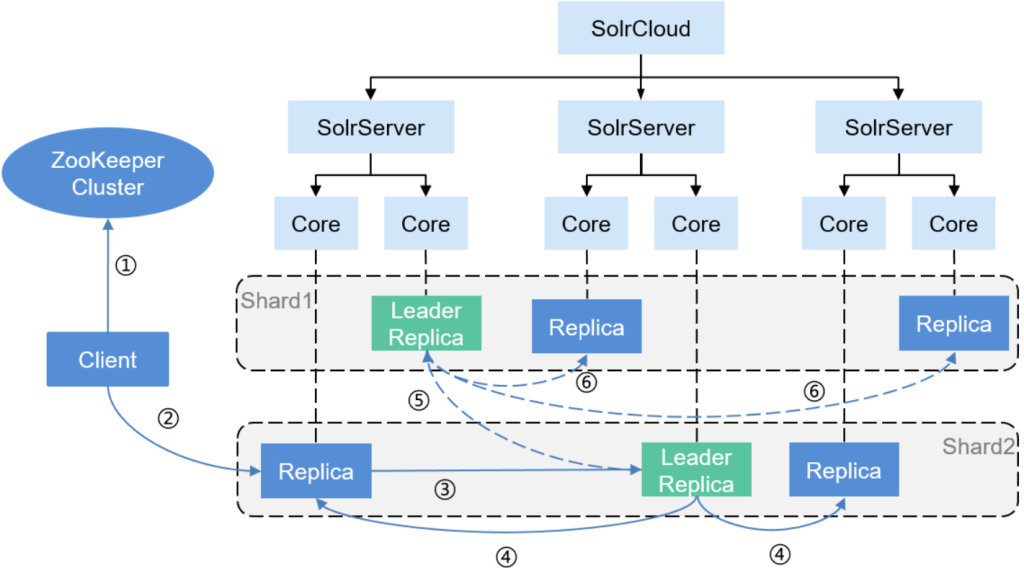
4. Scalability and Distribution (SolrCloud)
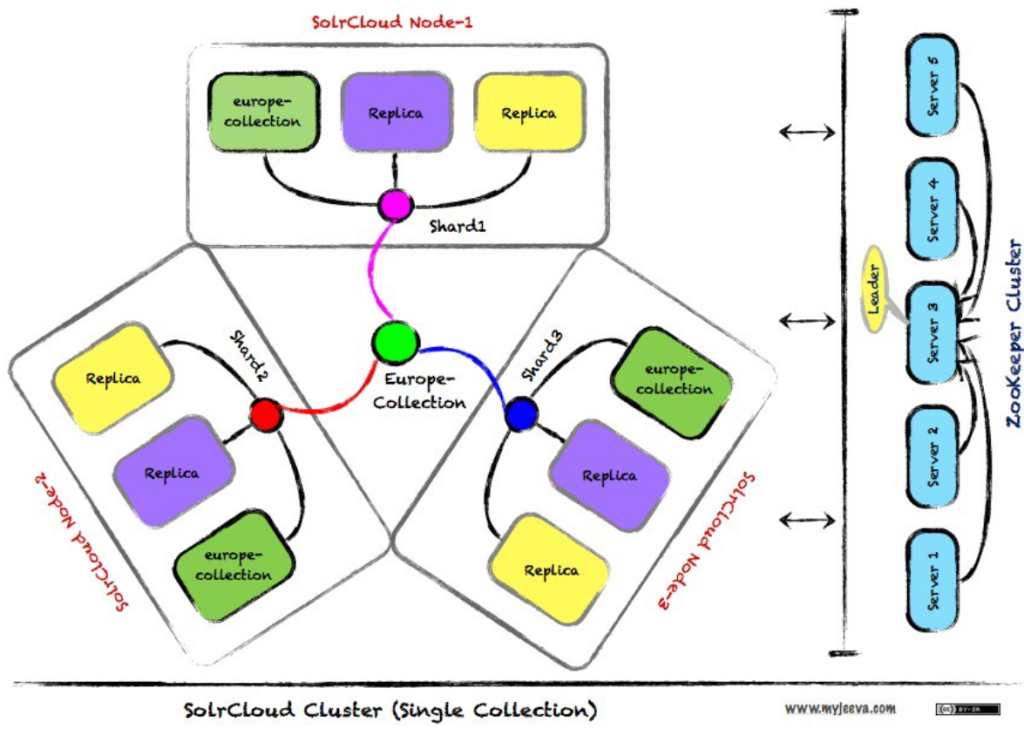
- Cluster Management: Solr can be run in a distributed mode known as SolrCloud, which supports distributed indexing and search capabilities, automatic failover, and recovery. SolrCloud uses Apache ZooKeeper for cluster coordination and configuration management.
- Sharding and Replication: In SolrCloud, data is partitioned into shards for horizontal scaling and each shard can have one or more replicas for high availability and load balancing.
5. Administration and Management
- Admin Interface: Solr comes with a web-based administration interface that allows users to manage their indices, configure schemas, monitor system status, and execute queries.
- APIs and Integration: Solr provides extensive APIs for managing the lifecycle of documents and configurations, and for integrating with other applications and frameworks.
Apache Solr Architecture?
Apache Solr’s architecture is designed for high performance, scalability, and flexibility, making it suitable for a wide range of applications from simple full-text searching to complex enterprise search systems. Below, I outline the main components and structure of Solr’s architecture:
1. Core Components
- Solr Core: The fundamental unit of Solr, a Solr core contains the actual index along with its configuration files (
solrconfig.xml,schema.xml), which dictate how data is indexed and queried. A single Solr instance can host multiple cores, allowing different datasets to be managed separately under a unified server setup.
2. Indexing and Analysis
- Document: The basic unit of data in Solr, consisting of fields that store the data in key-value pairs.
- Field and Field Types: Each document is composed of fields, which are defined in the schema with specific field types that dictate how the data in each field is indexed (e.g., text, integer, date).
- Analyzer: Analyzers process text fields through tokenizers and filters to prepare text for indexing. This can involve processes like lowercasing, removing stop words, applying synonyms, etc.
3. Query Processing
- Request Handler: These are endpoints that interpret and process incoming queries, turning user requests into actions Solr can execute. They can be highly customized.
- Search Components: Components such as faceting, highlighting, and spell checking enhance search capabilities by processing search results or modifying query execution.
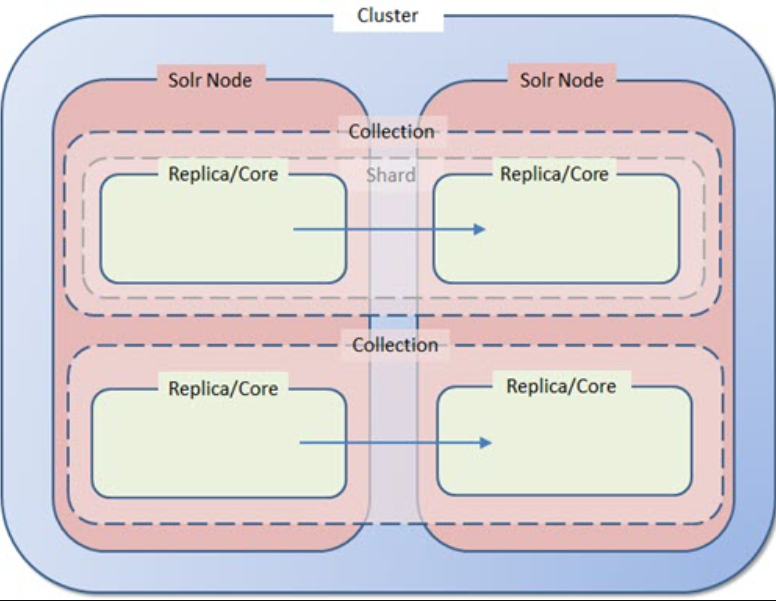
4. Distributed Architecture (SolrCloud)
- SolrCloud: A mode of Solr designed for distributed environments, providing scalability and fault tolerance through automated failover and recovery.
- ZooKeeper: SolrCloud uses ZooKeeper to handle distributed coordination, managing cluster state and configuration settings across nodes.
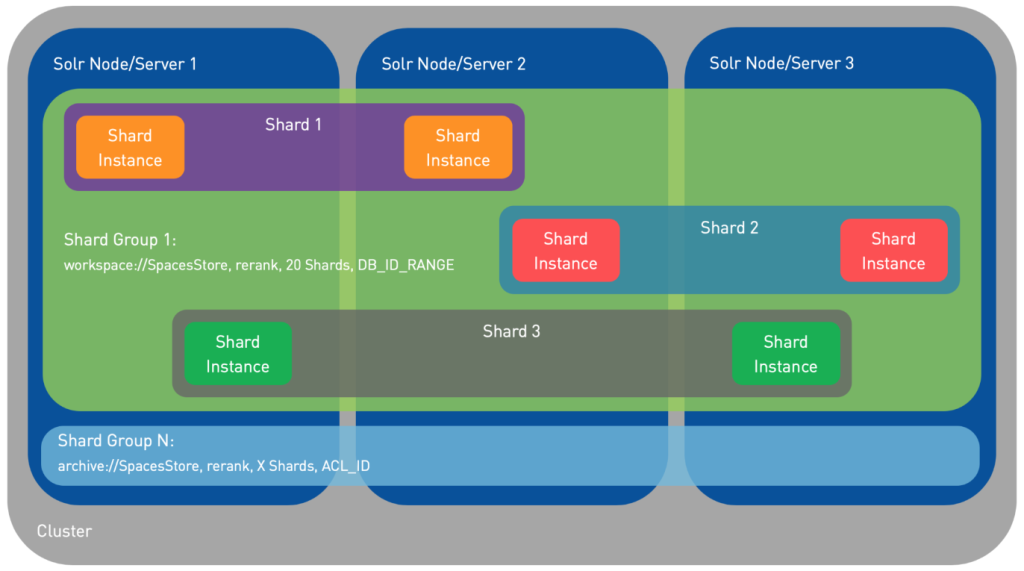
- Nodes: Each node in a SolrCloud setup is an instance of Solr running one or more cores.
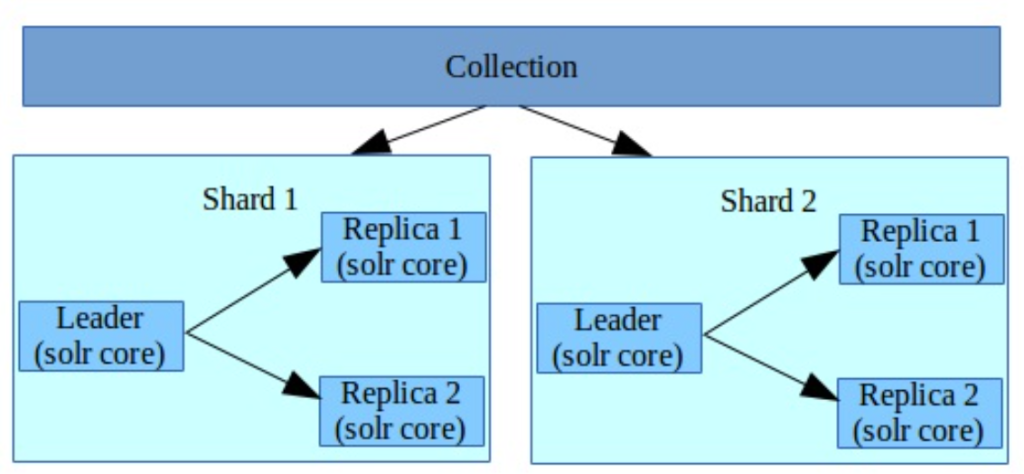
- Collections: In SolrCloud, collections are logical indices that span multiple nodes. They can be divided into shards for distributed indexing and searching.
- Shards: Shards are segments of a collection’s data. Each shard can be hosted on one or more nodes for load distribution and fault tolerance.
- Replicas: Replicas are copies of shard data. Having multiple replicas of each shard enhances the availability and speed of query responses by allowing queries to be load-balanced across replicas.
5. Scalability and Performance Optimization
- Caching: Solr employs various caches (filter cache, query result cache, document cache) to improve query response times by storing frequently accessed data in memory.
- Load Balancing: In a SolrCloud environment, load balancing can be managed through Solr itself or external load balancers to distribute queries and indexing load across nodes.
6. Interfaces and Integration
- Admin UI: Solr provides a web-based administration interface for managing cores, configurations, and monitoring system status.
- APIs: Solr offers a rich set of APIs (HTTP/XML, JSON, Java) for performing operations like indexing, querying, and configuration management programmatically.
7. Security
- Authentication and Authorization: Solr supports pluggable authentication and authorization to control access to its features, integrating with systems like Kerberos or basic authentication via HTTP.
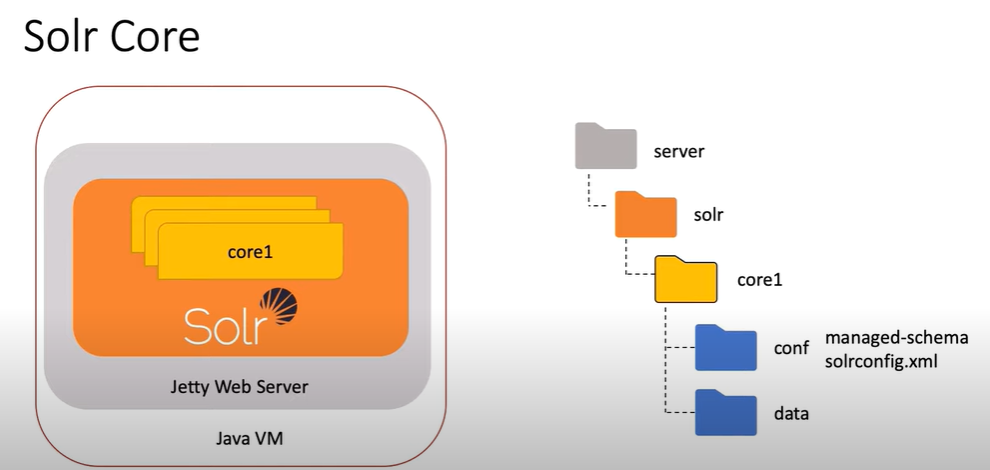
How Documents Stored in Apache Solr?
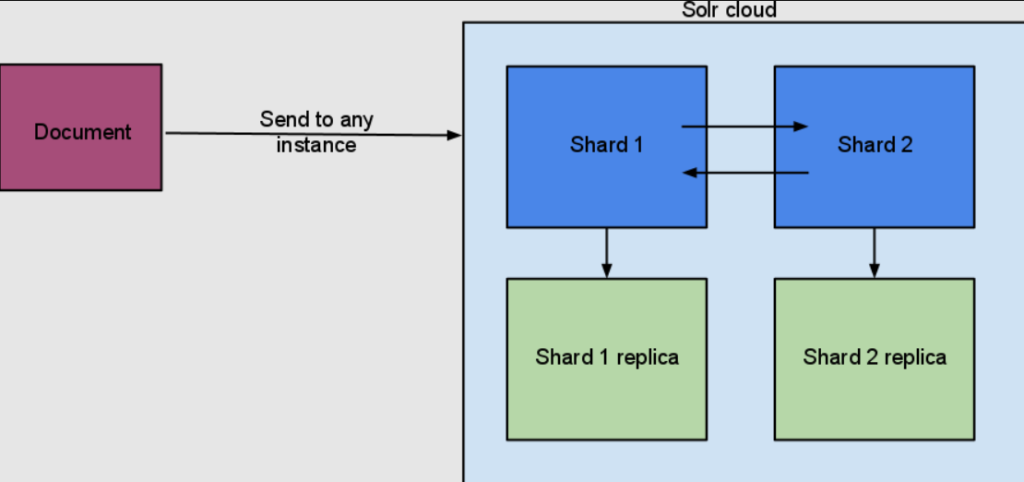
Apache Collection
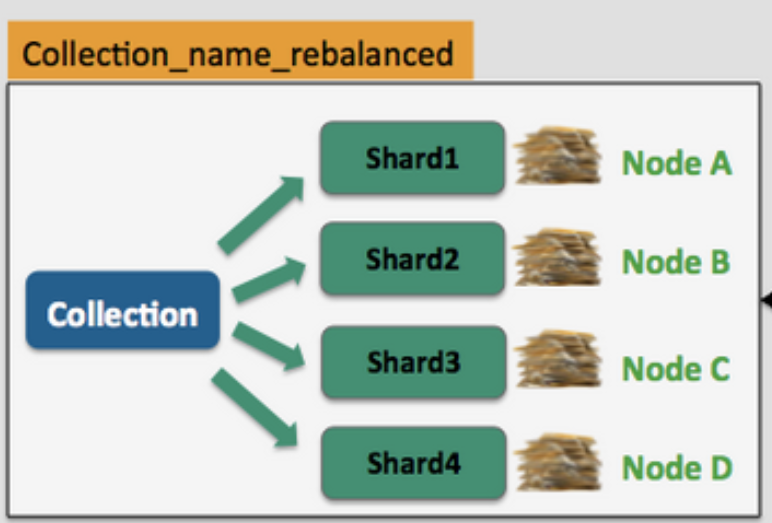
How Apache Solr Works?
Collection





Leave a Reply
You must be logged in to post a comment.