Introduction
Enterprise IT environments face unprecedented complexity due to distributed microservices, hybrid cloud architectures, and a relentless flood of telemetry data. Consequently, traditional operations teams suffer from severe alert fatigue, since legacy monitoring tools fail to separate critical signals from overwhelming background noise. To combat these operational challenges, professionals increasingly seek specialized AIOps Training to modernize their engineering workflows. By implementing advanced algorithmic frameworks, engineering teams can proactively address performance degradation before it impacts end-users. Therefore, learning these automated methodologies through platforms like AiOpsSchool empowers engineers to transform chaotic firefighting into structured, intelligent operations management.
Furthermore, infrastructure scales exponentially while human operational capacity remains static. This growing disparity creates hazardous blind spots, leading to prolonged system downtime and degraded user experiences. As a result, traditional manual intervention is no longer viable for enterprise-scale incident response. Forward-thinking organizations are rapidly adopting artificial intelligence for IT operations to bridge this operational gap. Ultimately, acquiring these automated skills allows engineers to build resilient, self-healing systems that thrive under high scale.
Navigating the Fundamentals: What Is AIOps?
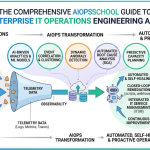
To understand this paradigm shift, one must first explore the foundational technology that redefines enterprise monitoring. Specifically, What is AIOps refers to the application of machine learning, big data, and advanced analytics to automate infrastructure operations. Instead of relying on static, human-configured thresholds, this methodology leverages continuous algorithmic analysis to interpret system behavior. Consequently, it ingests massive streams of historical and real-time data to find hidden patterns that indicate underlying technical degradation.
In addition, this framework acts as a central brain for your entire infrastructure ecosystem. It unifies disparate monitoring silos, bringing data from applications, databases, and network devices into a single analytical layer. By doing so, it eliminates blind spots and provides a holistic view of organizational health. Modern engineers utilize these automated platforms to shift from reactive firefighting to predictive, continuous system optimization.
Key Operational Concepts You Must Know
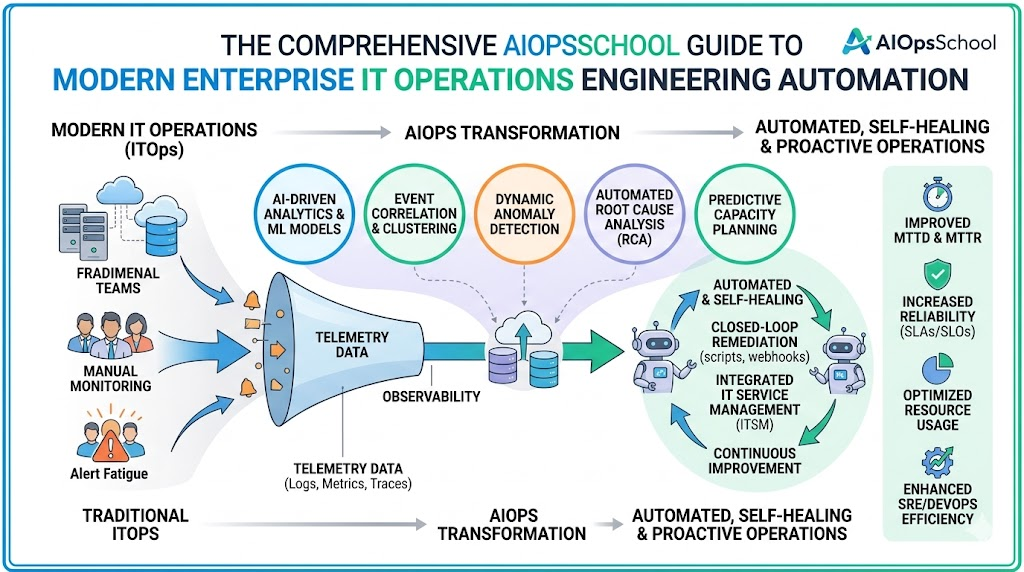
Mastering AIOps in IT operations requires a deep understanding of core telemetry and mathematical concepts. First, observability forms the cornerstone of this practice, demanding that systems expose their internal states clearly. Engineers achieve this by gathering three primary telemetry data types: logs, metrics, and traces. Specifically, logs provide a chronological record of discrete system events, metrics offer numerical performance measurements over time, and traces map the end-to-end journey of requests across distributed microservices.
Furthermore, event correlation plays a critical role in transforming raw telemetry into actionable insights. When a major infrastructure outage occurs, thousands of related alerts trigger simultaneously across various architectural layers. Consequently, advanced correlation algorithms group these redundant signals into a single, cohesive incident context. This automatic clustering prevents engineers from being overwhelmed by repetitive notifications during critical system failures.
Additionally, distinguishing between a normal baseline and an actual anomaly is vital for system stability. Machine learning models continuously analyze historical performance data to establish dynamic behavioral boundaries for every infrastructure component. As a result, when current metrics deviate significantly from these calculated baselines, the system flags an anomaly. This proactive identification allows operations teams to address hidden anomalies before they escalate into catastrophic customer-facing outages.
Finally, automation and remediation represent the ultimate maturity stage of modern infrastructure engineering. Once an anomaly is detected and correlated, automated systems trigger targeted playbooks to resolve the issue without human intervention. For instance, the platform can automatically restart a failing service container, clear a full disk cache, or provision extra cloud capacity. Therefore, combining deep telemetry analysis with automated execution creates a highly resilient, self-healing production environment.
Shifting Paradigms: AIOps for Beginners
Entering this field can feel overwhelming due to the massive intersection of data science and infrastructure engineering. However, starting with AIOps for beginners highlights that anyone with foundational IT skills can successfully master these advanced automation concepts. There has never been a better time to pivot toward intelligent operations engineering, given the rapid transformation of enterprise technology.
- Explosive Career Market Demand: Enterprises globally face severe shortages of engineers who understand both machine learning workflows and core infrastructure management.
- Eradication of Repetitive Operations: Embracing smart automation allows you to escape mundane, repetitive tasks like manual log analysis and constant on-call alert triage.
- Future-Proofing Engineering Skillsets: As cloud environments expand, legacy monitoring methods become obsolete, making data-driven automation the industry standard.
Moreover, introductory learning paths focus heavily on practical conceptual frameworks rather than complex mathematical modeling. Beginners learn how to configure out-of-the-box machine learning modules within existing corporate monitoring ecosystems. Consequently, this practical approach builds immediate operational confidence while delivering tangible business value. As you progress, you will naturally transition from consuming automated insights to designing custom algorithmic remediation playbooks.
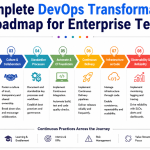
Decoupling the Technical Ecosystem: AIOps vs DevOps vs MLOps
To position this methodology correctly within modern enterprise technology, we must contrast it with other dominant engineering paradigms. While these frameworks often intersect, they serve completely distinct purposes across the software development lifecycle. Understanding these boundaries ensures that teams apply the right methodology to the correct technical challenges.
| Concept | Primary Focus | Core Question It Answers |
| DevOps | Streamlining code delivery pipelines and breaking down developer silos through continuous integration. | How can we deploy software updates faster and more reliably into production? |
| MLOps | Standardizing the lifecycle deployment, packaging, testing, and monitoring of machine learning models. | How do we operationalize, version, and maintain data science assets efficiently? |
| AIOps | Utilizing automated data analytics and machine learning to optimize live infrastructure environments. | How can we use intelligent algorithms to prevent production downtime automatically? |
Furthermore, DevOps establishes the foundational collaborative culture and delivery pipelines that allow software to flow smoothly into production. Meanwhile, MLOps provides the structured engineering discipline required to train, deploy, and monitor the predictive models themselves. In contrast, this operational framework utilizes those deployed models to ensure the underlying production infrastructure remains stable, performant, and resilient. Therefore, these three disciplines operate in harmony to support agile, high-scale digital enterprises.
Platform Implementation vs. Culture — What’s the Real Difference?
Many enterprise organizations mistakenly treat this transformation as a simple software installation project. However, achieving true maturity with AIOps Training requires a profound cultural shift alongside platform implementation. Simply purchasing an advanced software license and connecting it to your infrastructure will not resolve underlying operational systemic failures. Instead, organizations must completely redefine how teams collaborate, share information, and trust automated system insights.
Consequently, building deep organizational trust in automated algorithms forms a critical pillar of successful deployment. Traditional operations teams are accustomed to manually validating every alert and logging into servers to run individual diagnostic commands. Shifting to an automated paradigm means trusting machine learning models to identify root causes and execute automated remediation scripts. Without cultural training and gradual exposure, engineers will likely override or ignore the platform’s automated recommendations, rendering the technology useless.
Additionally, effective management of AIOps in IT operations demands a continuous commitment to cross-team data normalization and operational transparency. Siloed engineering teams often maintain separate monitoring tools, leading to fragmented context during major incidents. Culturally, teams must transition to a shared telemetry model where data flows freely across application, security, and infrastructure boundaries. This collaborative approach ensures that the central machine learning engine has access to the comprehensive data required for precise correlation.
| Operational Dimension | Platform Implementation Focus | Cultural Transformation Focus |
| Data Architecture | Deploying centralized collectors and connecting API endpoints across infrastructure. | Standardizing cross-team logging formats and committing to total data transparency. |
| Incident Response | Configuring correlation engines and setting up automated alert dashboard views. | Transitioning from manual validation to trusting algorithmic root cause detection. |
| Automation Adoption | Writing remediation scripts and integrating automated playbooks with orchestrators. | Overcoming fear of automated changes and establishing robust guardrails. |
| Team Structure | Providing access permissions to various infrastructure and application engineering teams. | Breaking down traditional silos to foster deep collaboration between SRE and DevOps. |
Ultimately, technology serves merely as an enabler for the broader cultural evolution of the engineering organization. Teams must actively redefine their daily operational habits, incident management workflows, and performance metrics to align with automated outputs. By combining rigorous platform configuration with comprehensive cultural upskilling, enterprises unlock the full predictive power of algorithmic infrastructure management.
Practical Capabilities: Core AIOps Use Cases
Implementing intelligent automation unlocks numerous practical capabilities that drastically improve daily enterprise infrastructure performance. By deploying specialized machine learning algorithms, operations engineering teams shift from manual validation to scalable, data-driven execution. Here are the core AIOps use cases that drive modern operational excellence:
- Continuous Anomaly Detection: Machine learning algorithms evaluate live telemetry streams against historical baselines to identify subtle performance deviations instantly. This continuous anomaly detection alerts teams to emerging software bugs or infrastructure degradation long before traditional static thresholds trip.
- Intelligent Event Correlation: The analytical platform ingests thousands of simultaneous notification signals during an infrastructure outage. Through automated event correlation, it compresses these redundant alerts into a single contextualized incident ticket, eliminating noise entirely.
- Advanced AIOps Root Cause Analysis: When multi-tier system failures happen, pinpointing the exact triggering component manually takes hours. Utilizing AIOps root cause analysis allows the system to trace dependencies across microservices and isolate the precise code deployment or hardware fault immediately.
- Predictive Capacity Planning: Instead of reviewing outdated monthly resource charts, algorithmic models analyze long-term utilization trends. This predictive capacity planning forecasts exactly when cloud storage, memory, or compute clusters will deplete, allowing for proactive scaling.
- Automated Remediation Execution: When well-defined infrastructure anomalies occur, the system triggers pre-approved software scripts to resolve the issue directly. This automated remediation clears system bottlenecks, scales clusters, or restarts services at midnight without requiring human intervention.
- Holistic AIOps in IT Operations: Integrating all these capabilities creates a comprehensive, intelligent ecosystem across the enterprise. Managing AIOps in IT operations ensures that application health, network performance, and cloud spend are continuously optimized via centralized data-driven intelligence.
Real-World Use Cases of Modern Operations
To illustrate these capabilities, consider a global e-commerce enterprise experiencing a sudden, massive database latency spike during a high-traffic holiday shopping event. Through advanced AIOps use cases, the platform instantly correlated the latency with a minor microservice code deployment rather than a hardware bottleneck. Consequently, this rapid AIOps in IT operations insight allowed the engineering team to rollback the specific deployment within minutes, preventing millions of dollars in lost transactions.
Similarly, a major multinational banking institution leveraged automated telemetry mapping to detect a subtle, distributed security anomaly across multiple geographic cloud regions. By applying sophisticated machine learning models, the platform isolated the anomalous credential behavior and executed automated remediation to quarantine the compromised nodes. As a result, this proactive intervention preserved data integrity and maintained continuous compliance without disrupting active consumer banking sessions.
Additionally, a high-growth SaaS provider utilized historical resource patterns to optimize its multi-cloud infrastructure spend. Their predictive analytics models accurately forecasted upcoming computing demand variations based on historical user sign-on trends throughout the fiscal year. Therefore, the operations team automated their scaling schedules perfectly, reducing idle cloud infrastructure costs by over thirty percent while guaranteeing consistent application performance.
Navigating the Technology Landscape: AIOps Tools You Should Know
Building a modern automated infrastructure stack requires deep familiarity with the leading industry software solutions. Engineers must understand which platforms align best with their specific organizational architectures and operational maturity levels. Reviewing this structured AIOps tools list helps teams categorize and select the ideal platforms for their technical requirements:
Monitoring and Observability Platforms
- Dynatrace: Utilizes a powerful, proprietary causal AI engine named Davis to deliver precise, real-time root cause analysis across complex enterprise application stacks.
- Datadog: Offers comprehensive, cloud-native visibility by combining full-stack telemetry monitoring with Watchdog, its native machine learning analytical assistant.
- ScienceLogic: Specializes in hybrid-cloud infrastructure monitoring, providing automated context and deep visibility across legacy data centers and modern cloud endpoints.
Event Correlation and ITSM Tools
- BigPanda: Excels at ingesting massive volumes of fragmented alerts from disparate tools and using machine learning to cluster them into clean, actionable incidents.
- PagerDuty: Integrates advanced digital operations management with automated event intelligence to streamline developer on-call schedules and accelerate incident response.
- Splunk IT Service Intelligence: Leverages deep log analytics and predictive machine learning models to prevent outages and optimize service health dashboards.
Open-Source Stacks and Frameworks
- Prometheus and Thanos: Provides robust, highly scalable metric collection and long-term storage capabilities, serving as the open-source foundation for custom anomaly modeling.
- Elastic Stack (ELK): Combines search capabilities with built-in machine learning features to detect anomalies within massive, unstructured enterprise log collections.
Cloud-Native Automated Services
- Amazon DevOps Guru: Leverages years of operational data from Amazon Web Services to automatically detect anomalous behavior and recommend specific architectural fixes.
- Google Cloud MQL Anomaly Detection: Provides built-in algorithmic capabilities within Cloud Monitoring to identify unexpected metric deviations across enterprise Google Cloud environments.
To master these complex platforms effectively, starting an organized AIOps Tutorial is the natural next step for modern operations engineers. These tutorials guide you through installing telemetry collectors, configuring correlation engines, and establishing automated incident workflows. Consequently, gaining hands-on experience with these diverse platforms ensures your infrastructure remains highly performant and resilient.
Common Mistakes in Operations Engineering
Transitioning to automated infrastructure management presents several hidden obstacles that can derail corporate implementation efforts. Identifying these pitfalls early allows engineering leaders to design robust mitigation strategies. Here are the most frequent mistakes made when managing AIOps in IT operations:
- Flooding the Platform with Unfiltered Telemetry Data: Ingesting dirty, un-normalized logs results in inaccurate algorithmic baselines and flawed conclusions. The quick fix requires enforcing strict data validation and normalization standards across all application logging frameworks before feeding data to the machine learning engine.
- Treating Automation as a Set-and-Forget Software Solution: Assuming the system requires zero human oversight leads to drifted models and missed anomalies over time. The one-line lesson is that machine learning models demand continuous tuning, validation, and optimization to match evolving application architectures.
- Implementing Automated Remediation Too Early Without Trust: Executing powerful infrastructure scripts based on low-confidence alerts can inadvertently cause widespread system outages. To resolve this, teams must mandate a strict observation phase where automated recommendations are manually approved before enabling fully autonomous execution.
- Ignoring Team Feedback and Lacking Cross-Functional Buy-In: Forcing new automated platforms on operations engineers without proper training leads to low adoption and cultural resistance. The solution involves involving on-call engineers early in the tool selection process and demonstrating immediate quality-of-life improvements, such as alert noise reduction.
- Failing to Connect Analytical Output to Precise Root Causes: Relying on vague anomaly notifications leaves engineers guessing during critical infrastructure outages. Operations teams must ensure the correlation engine performs deep AIOps root cause analysis to point directly to the failing line of code or hardware asset.
Driving Operational Excellence: AIOps for SRE
Site Reliability Engineering focuses deeply on maintaining system availability, scalability, and performance through rigorous software engineering principles. Consequently, integrating AIOps for SRE acts as a powerful force multiplier for achieving critical organizational reliability metrics. By replacing manual incident investigation with automated analytics, reliability teams can maintain strict Service Level Objectives with minimal stress.
Furthermore, this automated framework directly impacts the most critical lifecycle metrics: Mean Time to Detection and Mean Time to Resolution. When a complex microservice failure occurs, automated anomaly detection drops the detection time from hours to mere seconds. Simultaneously, intelligent correlation engines isolate the root cause immediately, allowing remediation scripts to resolve the issue and drastically shrink resolution times. Therefore, minimizing these metrics ensures that enterprise applications consistently protect their customer-facing availability targets.
Additionally, modern reliability teams utilize predictive data analytics to safeguard their strict error budgets. Instead of reacting after a Service Level Indicator is breached, machine learning models forecast burn rates based on real-time infrastructure usage trends. If a sudden resource consumption pattern threatens the monthly availability budget, the platform alerts the SRE team proactively. As a result, engineers can safely deploy new application features without compromising the overall stability of the production ecosystem.
Seeing AIOps in Action
To understand the practical power of this methodology, let us examine a detailed operational scenario inside a modern financial processing firm.
The Problem
During a high-volume trading window, a critical transaction clearing system began dropping five percent of inbound user requests. Traditional static monitoring tools flooded the on-call engineering team with over four hundred disconnected alerts across network, database, and application layers. Consequently, the overwhelmed engineers scrambled to identify the actual source of the failure while transaction backlogs grew exponentially.
The Algorithmic Resolution
Fortunately, the organization had recently integrated intelligent automation into their infrastructure stack.
- Ingestion and Normalization: The central platform ingested all four hundred incoming alerts along with live application traces and system logs.
- Algorithmic Event Clustering: It instantly compressed the chaotic wave of alerts into a single, high-severity operational incident context.
- Advanced Root Cause Analysis: Utilizing AIOps root cause analysis, the platform traced dependencies and bypassed the noisy network alerts. It isolated a specific database connection pool lockup caused by a bad code deployment that occurred ten minutes prior.
- Autonomous Remediation Trigger: Rather than waiting for a human decision, the platform executed a pre-validated automated remediation playbook.
- System Recovery: The script automatically rolled back the faulty deployment and safely restarted the blocked database instances.
The Measurable Result
Through this automated AIOps in IT operations workflow, the entire incident lifecycle concluded in less than ninety seconds. The Mean Time to Resolution dropped by over ninety-five percent compared to manual troubleshooting methods, saving the firm thousands of dollars in regulatory non-compliance penalties. Ultimately, the engineering team avoided stressful firefighting and maintained their strict application availability commitments.
How to Become an Operations Expert — Career Roadmap
Transitioning into an elite automation role requires a structured approach to acquiring both software engineering and data science skills. Professionals cannot simply rely on legacy system administration experience in today’s cloud-native landscape. Following this defined roadmap helps you systematically build the expertise required to excel in modern enterprise environments:
- Master Core System and Telemetry Foundations: Begin by gaining deep experience with Linux administration, containerization, and the fundamentals of cloud architecture. Learn to manually configure basic log collection, system metrics gathering, and distributed tracing across application environments.
- Acquire Structured Training and Skills: Dedicate focused time to formal education by enrolling in comprehensive AIOps Training programs. This step ensures you understand algorithmic pattern matching, machine learning basics, and automated event clustering methodologies.
- Engage in Comprehensive Practical Tool Practice: Build hands-on labs using enterprise-grade monitoring tools and open-source analytics platforms. Practice setting up dynamic baselines, writing automated remediation playbooks, and managing real-world event correlation rules.
- Complete a Dedicated Learning Curriculum: Enroll in a specialized AIOps Course to deepen your structural knowledge of predictive capacity planning and advanced root cause analysis. This structured curriculum bridges the gap between raw data science concepts and daily production operations.
- Validate Your Industry Expertise: Earn an official AIOps Certification to demonstrate your technical competency to global enterprise organizations. Achieving this credential solidifies your position as a forward-thinking operations engineer ready for senior infrastructure roles.
Finally, long-term career growth involves continuously specializing in fields like Site Reliability Engineering, platform engineering, or automated cloud architecture. As enterprise systems grow more complex, professionals who hold verified certifications will command the highest industry compensation. Therefore, committing to a continuous, structured learning path ensures your engineering skillset remains highly relevant for decades to come.
Frequently Asked Questions
- What are the primary prerequisites before starting an official AIOps Course?Candidates should possess a foundational understanding of core IT operations, basic cloud infrastructure architecture, and general system monitoring concepts. Familiarity with basic scripting languages like Python or Bash is highly beneficial but not strictly mandatory for introductory modules.
- How does earning an official AIOps Certification impact my career path?Achieving an AIOps Certification validates your ability to manage complex, data-driven automation platforms within modern corporate environments. Consequently, it dramatically enhances resume credibility, opens avenues for senior SRE or DevOps roles, and provides substantial leverage during salary negotiations.
- What is the core structural focus of an AIOps Foundation Certification program?An AIOps Foundation Certification focuses heavily on core terminology, telemetry data structures, dynamic baseline mathematics, and basic event correlation patterns. It provides the essential conceptual grounding required before moving into advanced automated remediation and custom machine learning model deployment.
- Can traditional systems administrators transition smoothly into this specialized field?Yes, traditional administrators can transition successfully by systematically upskilling in cloud-native technologies, automated scripting, and algorithmic data analysis. Transitioning allows engineers to shift away from manual infrastructure maintenance and embrace scalable, software-driven operations management.
- How long does it typically take to complete a comprehensive AIOps Course?Most structured courses span between four to eight weeks, depending on the depth of the practical lab exercises and tool configurations included. This timeline allows students to thoroughly digest theoretical machine learning frameworks while building real-world experience on enterprise observability platforms.
- Does this methodology completely replace human operations engineering teams?No, this technology is designed to augment human engineers by eliminating repetitive tasks and providing precise analytical insights. It empowers operations teams to focus on strategic architectural improvements, proactive security design, and system optimization rather than constant manual alert triage.
Moving Ahead: Why Get an AIOps Certification?
Enrolling in an official AIOps Certification program provides immediate professional advantages in a highly competitive technology market. As corporations retire legacy monitoring systems, they actively seek engineers who hold validated credentials in automated operations engineering. This certification proves to hiring managers that you possess both the theoretical knowledge and practical expertise required to manage algorithmic workflows.
Furthermore, pursuing an AIOps Foundation Certification establishes a structured learning path that eliminates the confusion of self-directed study. Instead of guessing which data science or infrastructure concepts matter, candidates follow a curated curriculum designed by industry experts. This rigorous training builds a deep conceptual foundation in telemetry analysis, event correlation, and automated remediation. Therefore, obtaining these verified credentials accelerates your career trajectory and positions you as a leading expert in modern infrastructure automation.
Where to Learn AIOps
Navigating your professional upskilling journey requires access to world-class educational resources and structured laboratory environments. AiOpsSchool provides a comprehensive ecosystem tailored to help engineers master advanced automation concepts seamlessly. Their training catalog covers every stage of operational maturity, ensuring you gain actionable skills that translate directly to corporate production environments.
- AIOps Training: Deep-dive training programs focusing on real-world implementation strategies, cultural transformation methodologies, and full-stack observability architecture.
- AIOps Course: Structured learning paths featuring hands-on labs where you configure live machine learning engines, design dynamic baselines, and build automated remediation scripts.
- AIOps Certification: Globally recognized credentials that validate your technical competency in data-driven operations engineering and boost your marketplace visibility.
- AIOps Tutorial: Step-by-step introductory guides designed to help beginners deploy telemetry collectors and understand event correlation mechanics quickly.
Final Thoughts
Embracing automated infrastructure engineering is no longer an optional luxury for technology professionals; it is an absolute necessity for modern career survival. As enterprise architectures continue to expand, legacy manual monitoring practices will completely disappear from the industry landscape. Committing to comprehensive AIOps Training ensures you remain at the absolute forefront of this inevitable infrastructure revolution. Validating your technical skills with an official AIOps Certification establishes your authority as an expert capable of guiding enterprises through complex automation transformations. Explore the advanced learning pathways available at AiOpsSchool.com to accelerate your journey toward mastering intelligent IT operations.


Leave a Reply
You must be logged in to post a comment.